|
|
今天给大家分享两篇来自ACL 2022会议和TPAMI 2021期刊上的论文,探究情感识别中的迁移学习问题。第一篇论文探究了利用prompt tuning解决跨领域文本情感分类的效果;第二篇论文提出了统一的跨域人脸表情识别benchmark。
分享作者:黄兆培、张峰源
1. Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis
发表会议:ACL 2022
本文关注于跨领域文本情感分析问题。该类问题一般采用一个带情感标签的源领域文本数据集训练模型,并通过领域自适应的方式将模型迁移到无标注的目标领域上测试。传统的文本领域自适应方法包括基于枢轴词(pivots)的迁移方法以及基于对抗训练的方法。近期,也有一些工作探究了利用预训练模型解决跨领域问题的方式,如[1]中采用特征适应模块将预训练模型的高层特征和迁移性更强的中间层特征相结合用于情感分类,[2]中将预训练模型继续在目标域数据上做无监督的MLM任务以适应目标领域分布。与上述工作不同的是,本文探究了利用prompt tuning解决跨领域文本情感分类的效果。
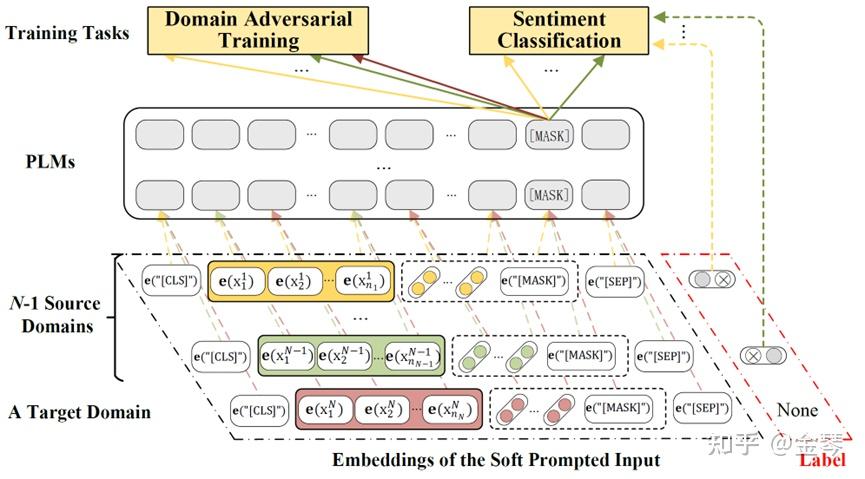
本文提出的方法AdSPT
近期,“prompt tuning”的预训练模型利用方式得到了广泛应用,在文本分类的相关任务上也取得了优异的表现。常用的一种prompt做法是在输入语句后加入固定的提示词模板以及遮蔽词(例如在输入语句后加入“It was [MASK]”),根据模型在[MASK]位置上的特征表示预测语句的类别。这种基于固定提示词模板的做法被称为“hard prompt”。
然而本文作者认为,在跨领域情感分类任务中,对于不同领域的文本使用同一套提示词模板可能会导致[MASK]位置上的特征具有较大的领域相关性。因此本文采用soft prompt的方式,即将固定的提示词模板替换为k个可学习的向量(本文中k=3)。对于不同领域的文本输入,soft prompt对应的向量可以更灵活地编码每个领域内的特征,从而为[MASK]位置上要预测的情感词提供与特定领域相关的提示。另一方面,本文加入了对抗训练的过程,使得[MASK]位置上的特征表示能够尽可能混淆判别器对于领域的预测,从而使得该特征表示具备更强的跨领域不变性,实现基于prompt的跨领域情感分类。
本文的对比实验表明,在跨领域文本情感分析任务上,采用prompt tuning的方式相比fine-tuning和在目标域上进行task adaptive pre-training的方式能够取得更好的效果。消融实验中也证明,无论是在单源域还是多源域的迁移设置下,soft prompt的效果都优于hard prompt。
References:
[1] Ye H, Tan Q, He R, et al. Feature Adaptation of Pre-Trained Language Models across Languages and Domains with Robust Self-Training[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 7386-7399.
[2] Karouzos C, Paraskevopoulos G, Potamianos A. UDALM: Unsupervised Domain Adaptation through Language Modeling[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 2579-2590.
2. Cross-Domain Facial Expression Recognition: A Unified Evaluation Benchmark and Adversarial Graph Learning
发表期刊:TPAMI 2021
本文认为目前很多人脸表情识别数据集间缺乏数据一致性,从而阻碍了模型泛化性的提升。目前一些跨域人脸表情识别(Cross-Domain Facial Expression Recognition, CD-FER)的方法能够较好解决跨域知识迁移的问题,但是模型验证缺乏一致性。因此,本文提出统一的跨域人脸表情识别验证benchmark。
作者认为目前基于对抗学习的方法都仅仅考虑到提取并对齐整体特征,并没有关注一些更易迁移的局部特征,而这些局部特征能够帮助模型更细粒度地理解人脸图像。由此,作者基于GCN提出跨域人脸表情识别模型AGRA,通过图来学习整体和局部特征间的联系,并通过对抗网络对齐整体和局部的特征分布。
下面是本文模型中图的构造方法。作者提出两种图:域内图和域间图。图中结点的定义如下:
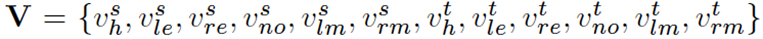
作者根据FAU所在区域将人脸划分为不同的区域:left eye (le), right eye (re), nose (no), left mouth corner (lm), right mouth corner (rm),另外下标h指的是整体特征。定义域内图和域间图的邻接矩阵如下:域内图包括两种连接方式:整体与局部、局部与局部;域间图包括三种连接方式:整体与整体、整体与局部、局部与局部。
作者对域内图和域间图分别设置GCN模块:Intra-domain graph与Inter-domain graph。首先通过Intel-domain graph学习源域和目标域的域内整体局部特征的关系,在此基础上通过Intra-domain graph继续学习源域和目标域的域间整体局部特征关系,最终通过判别器与分类器模块对齐特征。为了充分利用类别信息,本文逐类别对齐源域目标域数据。图中上下两个网络均共享参数,分类器G、特征提取器F、判别器D均共享参数。
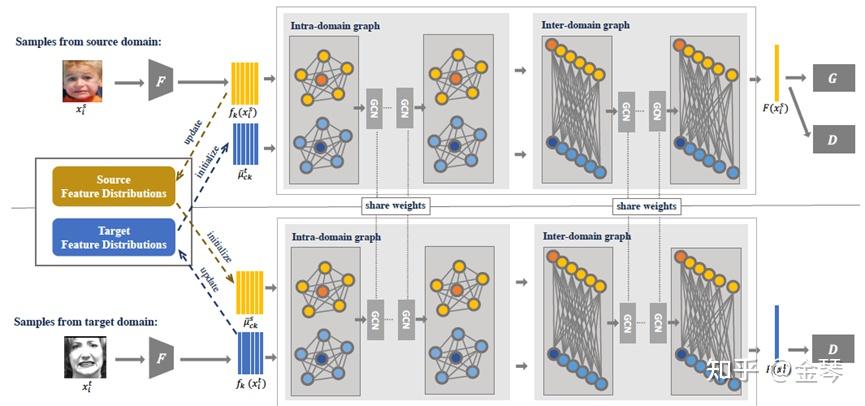
对于模型输入端源域、目标域特征分布,作者利用K-means对每个领域中的样本进行聚类,并将每个类别样本的均值作为该类别特征分布的初始值。在后续的训练中,采用移动平均的方式动态更新每个类别的特征分布,并将其与源域/目标域特征一同作为模型输入进行对齐。
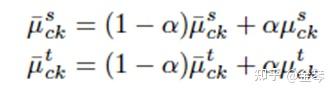 |
|


 发表于 2022-12-7 21:44:39
发表于 2022-12-7 21:44:39

