|
|
标题:Aspect Is Not You Need: No-aspect Differential Sentiment Framework for Aspect-based Sentiment Analysis
作者:Jiahao Cao, Rui Liu, Huailiang Peng, Lei Jiang, Xu Bai
来源:Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
1 Introduction
基于方面的情感分析 (ABSA) (Jiang et al., 2011) 旨在识别一段文本中每个特定方面术语的情感极性(即负面、中性或正面)(Hou et al., 2021; Dai et al., 2021; Li et al., 2021)。例如,在“食物很棒,但服务很糟糕”中,对“食物”的情绪是积极的,而对“服务”的情绪是消极的。我们需要预测句子中不同方面术语的情绪。
以前的工作通常采用预训练模型来提取句子和方面词拼接的嵌入。通过这种方式,预训练模型中的注意力机制增强了方面与其上下文之间的联系(Tang et al., 2016; Song et al., 2019)。实验结果验证了其吸引人的性能。然而,大规模原始语料库的预训练模型倾向于内化方面的内在属性(Huang 等人,2020),并给 ABSA 任务带来一些噪音。例如,对于句子“Desserts include flan and sopaipillas”,基于 BERT(Devlin et al,2019)的典型模型 BERT-SPC(Song et al,2019 年)倾向于将对“甜点”的情绪分类为正面,而标签是中性的。这是因为在预训练的语料库中,“甜点”经常与包含积极情绪的词一起出现,导致“甜点”这个词也内化了积极情绪。此外,使用交叉熵损失的传统文本分类方法存在一些缺点。一方面,交叉熵损失缺乏对噪声标签的鲁棒性(Zhang 和 Sabuncu,2018)和界限差的可能性(Elsayed et al,2018 年)而受到影响。另一方面,交叉熵损失忽略了不同情感极性之间的潜在关系。同时,由预训练模型(Li et al., 2020)导出的非光滑各向异性语义空间也带来了区分情感之间潜在关系的困难。
为了解决这些问题,我们从人类认知的角度分析了 ABSA 任务。人们在很多 NLP 任务中经常关注学习策略和特征表示,却忽略了人类和人工智能之间的概念组织。直觉上,人类在不知道方面含义的情况下仍然可以在 ABSA 任务中表现出色。如图 1 所示,在“我有一只美味的虾。 ”,也许我们不知道“虾”是什么(它是一种食物),我们也可以很容易地将这个词的情感极性归类为正面。因为我们可以通过上下文来判断切面的情绪。此外,在人类感知中,“积极”和“消极”是两种完全相反的情绪,而“中性”情绪介于两者之间。 “正面”和“中性”之间的距离显然比“正面”和“负面”更近。
受人类认知的启发,我们提出了无方面模板差分情感(NADS)框架。我们首先通过用特殊情感无偏字符“<aspect>”替换句子中的aspect术语来设计一个no-aspect模板,并利用no-aspect模板和原始句子之间的对比学习。这样,我们不仅可以消除原始句子中的情感偏差,还可以学习更广泛的句子模板,以增强我们框架的鲁棒性。此外,它帮助我们的 NADS 框架在不知道其具体含义的情况下判断切面的情绪,就像人类一样。然后,为了减少特殊字符“<aspect>”造成的语义损失,我们利用掩蔽的aspect预测来保留原始语义信息。此外,我们设计了差分情感损失来找到不同情感之间的不同距离,更好地区分不同的情感。我们的主要贡献是:
• 我们提出了无方面模板并利用无方面对比学习来考虑更广泛的句子模式并消除方面嵌入中的情感偏差。这也使我们的模型能够在不知道方面是什么的情况下预测方面的情绪,就像人类一样。
• 我们设计差分情绪损失来帮助我们更好地区分不同情绪之间的不同距离。此外,我们的差分情感损失可以使具有相同情感的样本尽可能靠近,而具有不同情感的样本则尽可能远离。 • SemEval 2014 的实验表明,我们的模型提高了三种典型 ABSA 方法的性能,并达到了新的最先进水平。此外,在方面鲁棒性测试集 ARTS 上的实验表明,我们的 NADS 模型可以大大提高模型的鲁棒性。
2 Related Work
基于方面的情感分析是一种细粒度的情感分类任务。最近,一些关于 ABSA 的工作集中在通过句法树来利用句法知识。 (Wang et al., 2020) 以方面术语为中心重塑了句法树,并利用关系图注意力网络对新的树结构进行了编码以进行情感预测。 (Hou et al., 2021) 在将 GNN 应用于结果图之前,结合了来自不同解析的依赖关系。
另一种趋势是利用各种注意机制来寻找一个方面及其上下文的语义关系(Tan et al., 2019; Li et al., 2018; Fan et al., 2018; Huang et al., 2018)。注意力机制有助于关注与方面相关的上下文并屏蔽不相关的上下文。此外,一些作品试图整合语法树和注意力机制。最近的工作 (Li et al., 2021) 利用双向仿射注意机制来融合来自句法树的句法信息和语义信息。
与此同时,预训练的语言模型 BERT (Devlin et al., 2019) 在许多 NLP 任务中取得了显着的性能。实验表明,在 ABSA 中使用 BERT 可以取得比使用 Word2vec (Mikolov et al., 2013) 和 GloVe (Pennington et al., , 2014)。然而,(Wang 等人,2021 年)表明,由预训练模型引起的方面的情感偏差可能会使 ABSA 任务感到困惑。他们利用外部情感知识 SentiWordNet (Esuli and Sebastiani, 2006) 为方面术语提取先前的三分类情感。然后他们提出了一个对抗网络来消除方面术语的先验情绪。然而,尚不清楚从 SentiWordNet 标记的方面情感极性是否与预训练模型中的情感偏差一致。此外,之前使用交叉熵损失的工作也忽略了不同情感极性之间的潜在关联。
在本文中,我们提出了一个无方面的模板,并利用对比学习来消除情感偏差并学习更广泛的句型来提高模型的鲁棒性。此外,我们设计了差分情感损失,以更好地区分不同情感之间的不同距离并聚类相同的情感。
3 Preliminaries
在本节中,我们使用因果推理(Pearl et al,2000;Robins,2003)来说明我们框架的理论基础。我们使用图 2 中描述的因果图来说明传统的 ABSA 方法和我们的 NADS 框架。因果图反映了变量之间的因果关系,我们使用“→”表示直接影响。对于 ABSA 任务,影响情感预测的因素包括我们需要预测的特定方面 A 和方面 C 的上下文。A 和 C 对 ABSA 任务都很重要,因为 C 包含情感信息,我们需要知道哪个方面 A 来预测情绪。
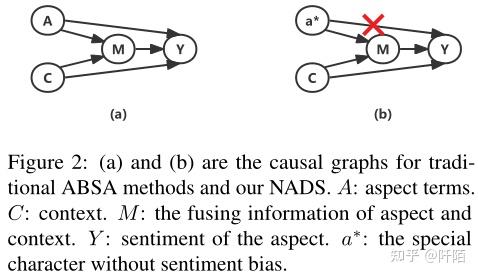
在传统方法的因果图中,如图 2 (a) 所示,上下文和方面通过 C → Y 和 A → Y 捕获情感的直接影响。融合信息通过 M 捕捉到 A 和 C 对 Y 的间接影响,即 A, C → M → Y 。如果 A 设置为 a 且 C 设置为 c,Y 将获得的预测结果为:
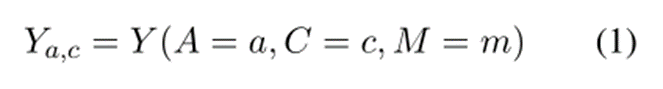
其中 m = Ma,c 表示方面 a 和上下文 c 融合的信息。根据这个公式,传统方法很好地考虑了方面及其上下文在 ABSA 任务中的作用。但是,在人类的认知中,aspect的具体含义并不影响人们对其情感的判断。传统方法忽略了方面情感偏差,这使得方面通过 A → Y 对预测结果 Y 产生直接影响。这可能会导致 ABSA 模型遭受方面和情感之间的虚假相关性,从而无法进行有效的推理。
在我们的 NADS 框架中,我们建议在 ABSA 中排除方面情绪偏差对 A → Y 的影响,如图 2 (b) 所示。我们利用一个没有情感偏差的特殊字符“<aspect>”来替换句子中的原始aspect,并使用maskedaspect预测来保留句子的原始语义信息。我们得到情绪预测 Y 为:
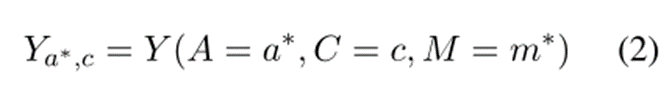
其中 a∗ = “<aspect >” 并且 m∗ = Ma∗,c。通过这种方式,我们消除了方面的情感偏差对预测结果的直接影响,并保留了原始语义信息。
4 Proposed NADS
在 ABSA 任务中,给定一个句子 S = {ω1, ω2, ..., ωτ , ..., ωτ+t, ..., ωn} 和一个方面项 A = {ωτ , ωτ+1, .. ., ωτ+t−1},目的是预测 A 在这个 S 中的情感极性。如图 3 所示,我们的 NADS 框架由三部分组成。我们首先提出无方面模板,并利用无方面模板和原始句子之间的对比学习来考虑更广泛的句型并消除方面嵌入中的情感偏差。然后,为了使带有特殊字符“<aspect>”的句子保留原始语义信息,我们利用了掩蔽的aspect prediction。最后,我们设计了差分情感损失来学习不同情感极性之间的不同距离。我们详细阐述了我们提议的 NADS 的细节。
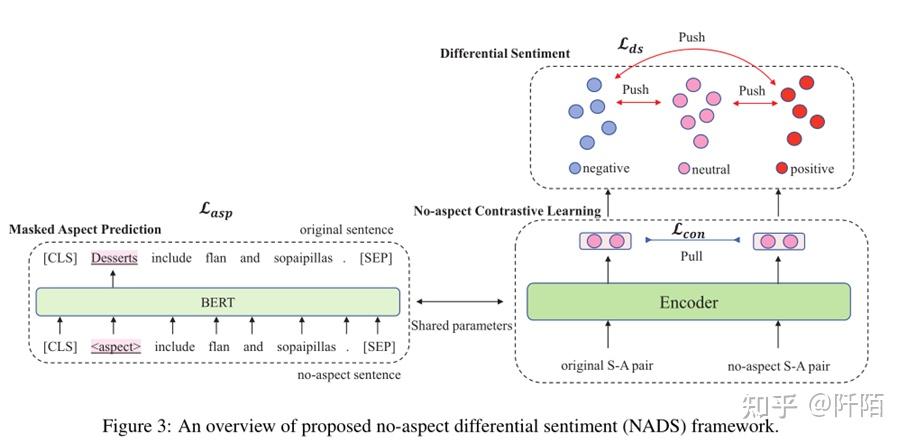
4.1 No-aspect Contrastive Learning
对于每个 {S, A} 对,我们使用一个特殊字符“<aspect >”来替换句子中的整个aspect term A。我们将无方面模板表示为 T :
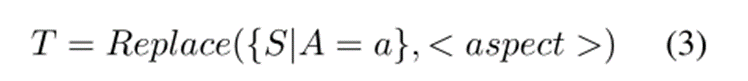
为了更好地使用无方面模板的信息并规范预训练的各向异性嵌入空间,我们利用原始句子和无方面模板之间的对比学习。具体来说,对于每个句子-方面对 (si, ai),我们将肯定句子表示为:

其中 Ti 是 si 的无方面模板。因此,我们得到了 (si, ai) 的正实例 (s+i , <aspect >)。我们通过编码器 fθ(·) 获得每个句子-方面对和正实例的特征表示:
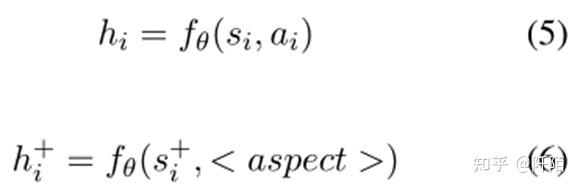
其中 hi 和 h+i 表示原始句子-方面对和正例的特征表示。在我们的 NADS 框架中,我们利用 BERT 通过输入方面术语和句子的连接来获得每个句子-方面对的嵌入。对于其他模型,我们使用他们的方法作为编码器来获取每对 (si, ai) 的嵌入。我们将小批量中的所有其他句子表示为否定实例,因此对比损失为:
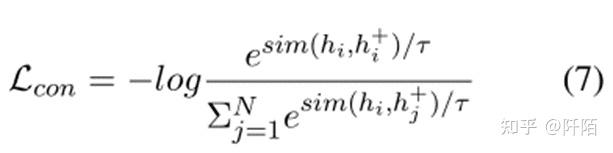
其中 τ 是温度超参数,sim(·) 是余弦相似度。 N 是批量大小。通过将原句与noaspect模板进行比较,我们消除了原句中aspect term造成的情感偏差,不仅学习了一个句子的信息,还学习了一组句型的信息。这有助于我们提高模型的鲁棒性。此外,对比学习帮助我们规范预训练的各向异性嵌入空间,为差异情绪损失做准备。
4.2 Masked Aspect Prediction
在 4.1 节中,我们利用“<aspect>”来构建无aspect 模板。但是,我们认为直接使用预训练模型中不存在的特殊字符“<aspect>”可能会给保留语义信息带来麻烦。因此,我们对特殊字符“<aspect>”使用masked aspect预测来保持原始语义。具体来说,我们通过使用“<aspect>”来掩盖aspect,并在我们的ABSA训练数据集中预测“<aspect>”位置的原始aspect术语。根据 (Hong et al., 2021),我们的目的是训练“<aspect>”的嵌入以保持完整的语义信息。对于我们的 NADS 框架,我们将“<aspect>”位置的嵌入表示为 h[<asp>]。我们将 h[<asp>] 输入到 softmax 层以预测原始方面:
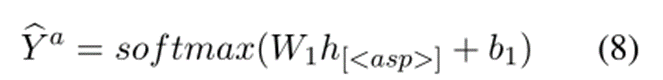
其中W1和b1是可训练参数,bY a 表示aspect word在其位置的预测概率。我们通过对每个“<aspect>”位置的预测的对数似然的累积来获得掩蔽的aspect预测损失:
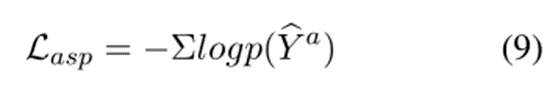
特别是,我们只预测“<aspect>”在句子中的位置。掩蔽的方面预测有助于我们在替换方面后保留句子的原始语义信息。
4.3 Differential Sentiment Loss
通过使用原始模板和无方面模板之间的对比学习对预训练的各向异性嵌入空间进行正则化后,我们设计了差分情感损失以更好地区分不同的情感。我们首先将标签嵌入到相同大小的 hi 中。我们将正面、中性和负面情绪标签转换为标签嵌入 L = {lpos, lneu, lneg}。句子-方面对嵌入 hi 和标签嵌入 li 之间的距离为:
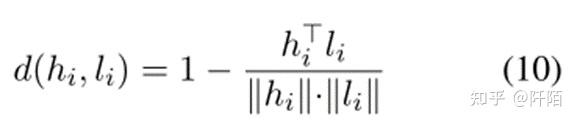
对于嵌入 hi 的每个句子-方面对,hi 与其标签 li 之间的距离应该比 L 中的其他标签嵌入更近。因此,我们利用三元组损失来使 hi 更接近正确的标签嵌入 li 并更接近另一个标签嵌入。对于每个 hi,正例是标签嵌入 li,负例是 L 中的其他标签嵌入。此外,在人类认知中,不同情感之间的距离是不同的。因此,我们为每个负面实例设置了一个特定的边距,以更好地区分不同情绪之间的不同距离。我们的差异情绪损失如下:
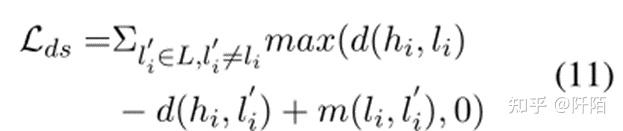
其中 m(li, l ′ i) 是标签 li 和 l ′ i 的特定边距。根据人类的认知,我们表示正面和负面情绪与中性情绪的距离应该相同,并且正面和负面之间的距离更远。因此,我们在模型中设置 m(pos, neu) = m(neg, neu) 和 m(pos, neg) > m(pos, neu)。与交叉熵损失相比,我们的差分情感损失可以通过区分情感之间的差异来更好地对情感进行分类。此外,我们的差异情绪损失可以联合训练模型和标签嵌入,使我们的框架更快收敛。为了判断句子-方面对的情感极性,我们利用余弦相似度来构建我们的评分函数:
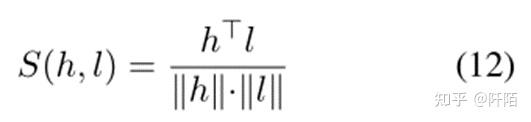
其中 h 是句子-方面对的嵌入,l 是标签的嵌入。我们将得分最高的 l 作为我们的预测结果。
我们的训练目标是最小化以下总目标函数:
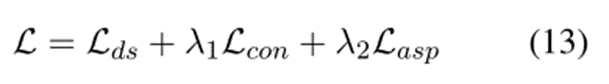
其中 λ1 和 λ2 是对比学习损失和掩蔽方面预测损失的权重。
5 Experiments
5.1 Datasets
Restaurant and Laptop reviews from SemEval 2014 Task 4 (Pontiki et al., 2014). 移除了评论中“conflict”标签的句子。
5.3 Implementation Details
我们使用 bert-base-uncased 英文版。在 DualGCN (Li et al., 2021) 之后,我们使用 LAL-Parser (Mrini et al., 2019) 来获取 DualGCN+NADS 的依赖树。我们随机初始化三种情绪的嵌入,并在训练期间设置 λ1 = 0.4,λ2 = 0.1。对于我们的 NADS 框架,笔记本电脑和餐厅数据集的不同边距 (m(pos, neu), m(pos, neg)) 设置为 (0.4, 0.6), (0.4, 0.6)。在训练期间,我们使用 AdamW 作为优化器,并将学习率设置为 2 × 10−5。我们训练模型最多 15 个 epoch,批量大小为 16。
5.4 Comparison Results
我们利用准确性和宏观平均 F1score 来评估 ABSA 任务。为了更好地预测测试中的正确情绪,我们采用三种不同的方式来测试我们的 NADS 框架。
1)原始测试:利用原始方面和原始句子的连接作为输入,提取嵌入进行预测。
2)Noasp测试:利用“<aspect>”和no-aspect模板的连接作为encoder的输入。这种测试方法可以帮助我们判断模型是否能正确预测情绪像人类一样不知道相位的具体含义。
3)联合测试:使用Original测试模式和Noasp测试模式,得到每个句子-方面对的每个标签的分数,并在归一化后将相同标签的分数相加。
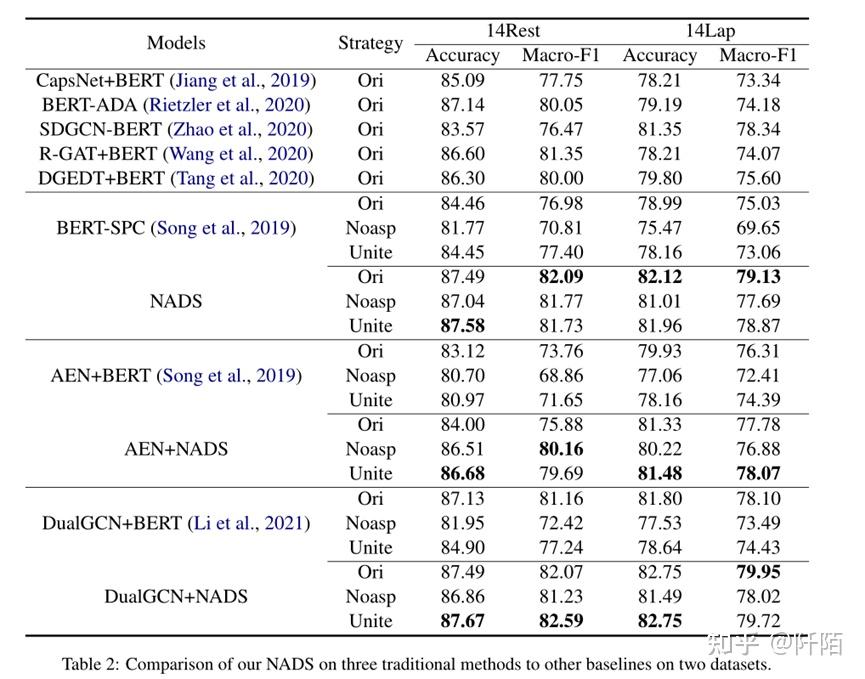
表 2 显示了我们的主要实验结果。正如我们所见,我们的 NADS 框架在笔记本电脑和餐厅数据集上的性能优于所有基线,并且在添加我们的 NADS 框架后,三种传统模型:BERT-SPC、AEN+BERT 和 DualGCN+BERT 的性能得到了提升。我们的 NADS 在餐厅/笔记本电脑上的表现优于 BERT-SPC 3.03%/3.13%。结果表明,我们的NADS框架有效地利用了人类认知的方式,在ABSA任务中发挥了更好的作用。与传统方法相比,我们的无方面模板消除了方面的情感偏差,学习了一组句型的更多信息,可以减少方面情感偏差带来的噪声,增强框架的鲁棒性。此外,我们的差分情感损失可以通过对比学习后区分这三种不同情感极性的差异来更好地对情感进行分类。对三种传统方法的实验也表明,我们的框架非常适合大多数现有模型并提高了它们的性能。
同时,根据Noasp测试的实验结果,传统方法的性能明显下降,不知道是什么方面。但是,我们的 NADS 框架仍然可以像人类一样在不了解方面的情况下表现良好。在 Noasp 测试模式下,BERTSPC 在餐厅/笔记本电脑上下降 2.69%/3.52%。相比之下,我们的 NADS 框架在餐厅/笔记本电脑上仅下降 0.45%/1.11%。我们还发现餐厅数据集上的 AEN+NADS 增加了 2.51%,而 AEN+BERT 下降了 2.42%。这说明我们的NADS在不知道aspect具体含义的情况下仍然可以表现良好。对比这三种测试模式,我们也可以发现Unite测试模式在不同的模型中都能达到最稳定的结果。
5.5 Ablation Study
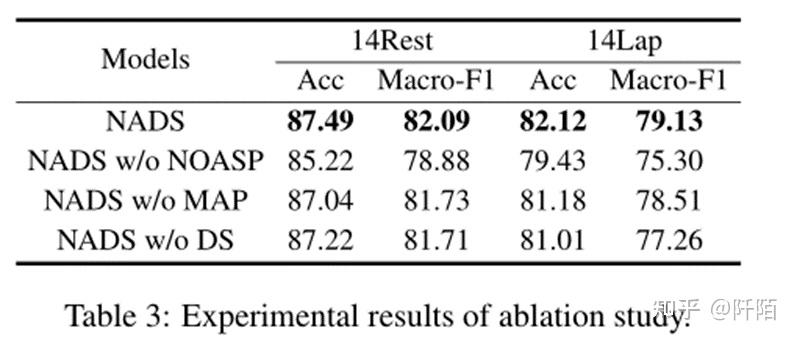
为了进一步研究不同模块在我们的框架中的作用,我们进行了广泛的消融实验。结果如表 3 所示。NADS w/o NOASP 表示我们只使用原始句子并删除对比学习。如果没有无方面模板和原始句子之间的对比学习,方面的情感偏差会使预测结果感到困惑,更重要的是,由于 BERT 模型的各向异性,差分情感损失将不起作用。因此,它在两个数据集上的性能都下降了。 NADS w/o MAP 意味着我们移除了 masked aspect prediction 模块,这样我们可能会丢失句子的原始语义信息。 NADS w/o DS 表明我们使用交叉熵损失函数而不是我们的差异情绪损失。如果没有差异情绪损失,模型就无法找到情绪之间的不同距离。实验表明,每个模块在我们的 NADS 框架中都是不可或缺的。
5.6 Selection of Margin
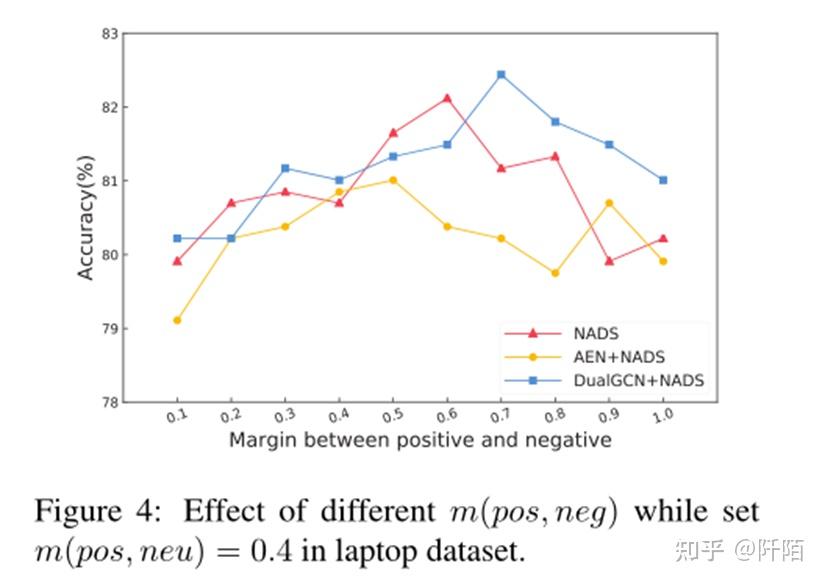
我们在差异情绪损失中尝试不同的边际。在我们的框架中,我们只考虑 m(pos, neu) 和 m(pos, neg)。图 4 显示了当我们在基于笔记本电脑数据集的 NADS 框架的三种方法中设置 m(pos, neu) = 0.4 时不同 m(pos, neg) 的准确度。可以看到,在 m(pos, neg) 逐渐增大的过程中,准确率先升高后降低。当 m(pos, neg) 设置为 0.6、0.5 和 0.7 时,这三个模型表现最好。该实验表明,距离正负补间确实比正负补间更远。它证明了我们差分情感损失的有效性。
5.7 Sentiment Bias Elimination
为了更好地理解我们的 NADS 框架消除情绪偏差的能力,我们找到了几个标签为中性的示例,并在表 4 中显示了它们在不同模型中的预测结果,其中 P、N、O 代表积极、消极和中性情绪.我们用红色突出显示方面的词。我们可以看到我们的 NADS 框架优于所有其他模型。对于第一个样本中的“steak”方面,之前的方法忽略了“steak”的积极情绪偏差,并错误地将情绪预测为积极。相比之下,我们的 NADS 通过无方面模板消除了积极情绪偏差,并将正确情绪预测为中性。此外,我们还在图 5 中显示了不良案例的分布。我们的 NADS 框架中的中性方面术语的不良案例明显少于 BERT-SPC。这证明了我们的 NADS 框架在消除情绪偏差方面的有效性。然而,我们的框架中仍然有一些中性的方面术语被错误地预测,如表 4 所示。一个可能的原因是,除了当前方面之外,句子中可能还有其他带有情感偏见的词。
5.8 Robustness Study
为了验证我们的 NADS 的稳健性,我们在 Aspect Robustness Test Set (ARTS) (Xing et al., 2020) 上测试了我们框架的稳健性得分。数据集根据三种策略丰富了 14Lap 和 14Rest:反转目标方面的原始情感(REVTGT),扰乱非目标方面的情感(REVNON),并生成更多与情感极性相反的非目标方面术语。目标 (ADDDIFF)。他们以原句和三个变体为一个单元。只有原句和所有变体都正确,单位才是正确的。计算数据集中单位的准确度作为最终的 Aspect Robustness Score (ARS)。我们比较了三个模型 be1606 在添加我们的 NADS 框架之前和添加 NADS 之后的 ARS。表 5 的结果表明,在加入我们的 NADS 框架后,模型的 ARS 得到了显着提升。我们添加 DualGCN 的 NADS 框架在餐厅和笔记本电脑上的表现明显优于其他模型,分别下降了 21.33% 和 21.93%。这表明我们利用人类认知的框架比其他模型具有更好的鲁棒性。此外,我们利用三种测试模式在 ARTS 上进行测试,如表 6 所示。我们可以看到,AEN+NADS 模型在餐厅和笔记本电脑上使用原始测试模式时分别下降了 57.39% 和 44.18%。但是,在使用 Noasp 测试模式时分别下降了 26.51% 和 22.34%。在整体方案中,Noasp 测试模式和 Unite 测试模式在 ARTS 上比 Original 测试模式可以得到更稳定的结果。在测试中使用无方面模板可能是一种更稳定的稳健性测试方法。
6 Conclusion
在本文中,我们针对ABSA任务提出了一个更符合人类认知的NADS框架。我们的 NADS 框架利用无方面对比学习来消除方面的情感偏差并增强句子表示。此外,我们构建了一个差分情感损失,通过区分情感极性之间的不同距离来更好地对情感进行分类。大量实验表明,我们的 NADS 框架提升了三种典型的 ABSA 方法并优于基线。此外,即使我们不知道方面是什么,我们的 NADS 框架仍然可以很好地执行。对鲁棒性数据集的测试表明,我们的 NADS 框架显着提高了模型的鲁棒性。 |
|


 发表于 2022-9-23 08:31:54
发表于 2022-9-23 08:31:54

